InfluxDB ist eine Datenbank, die spezialisiert ist auf der Speicherung und Analyse von Zeitreihendaten. Das Datenmodell ist optimiert, um große Datenmengen auf der Zeitachse darzustellen.
Bisher schreibe ich meine Daten von der Solaranlage und einigen home automation Geräten in eine SQL-Datenbank. Nach nun mehr als anderthalb Jahren wächst diese Datenbank kontinuierlich. Durch das Wachstum der Datenbank leidet auch irgendwann die Performance.
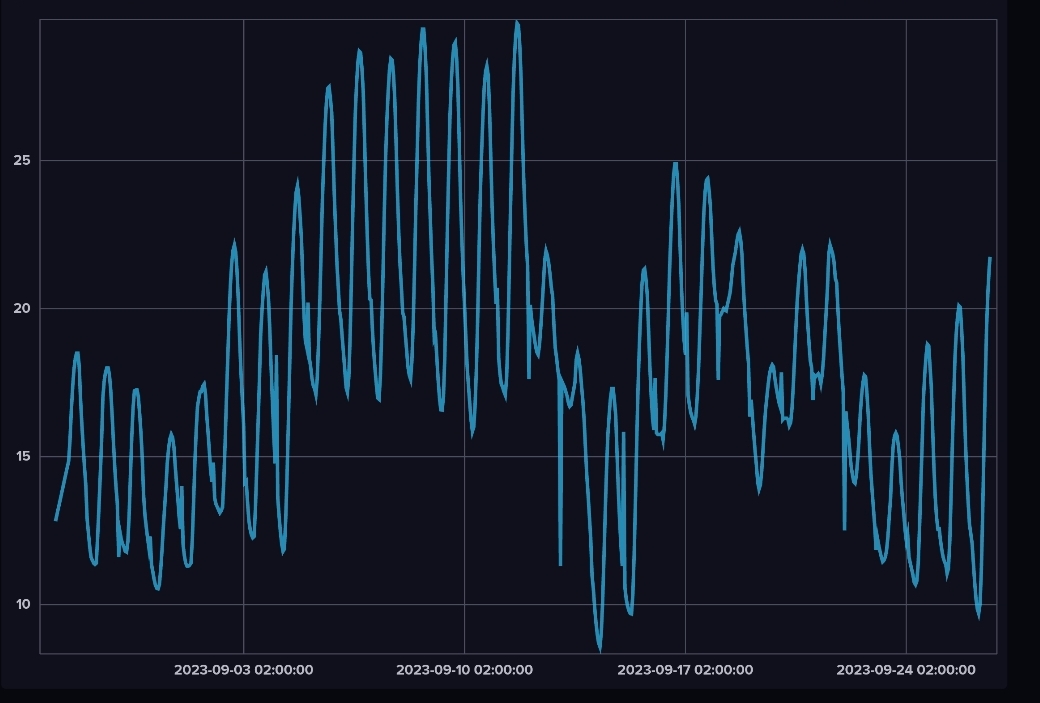
Auf der Suche nach einer Alternative oder einer Erweiterung habe ich eine InfluxDB in einem Docker Container installiert. Zur Überprüfung der Funktion habe ich einen Export aus meiner SQL-Datenbank mit den Temperaturdaten für Schloß Holte-Stukenbrock in die InfluxDB Instanz geladen. Der Zeitraum umfasst die letzten 30 Tage.
Das Datenbank Webfrontend ermöglicht eine Visualisierung auf dem Zeitstrahl und auch eine einfache Art der Analyse ähnlich wie in Grafana.
Die SQL-Datenbank hat sich bewährt und läuft stabil. Prinzipiell gibt es keinen Grund für einen Systemwechsel. Selbst wenn die SQL-Datenbank um weitere Gigabyte anwächst, sollte das technologisch kein Problem darstellen.
Wie kommen jetzt die Daten in die InfluxDB und wie lässt sich ein Performance Vergleich bewerkstelligen?
Ich konzentriere mich mal auf die Wetterdaten und diese liegen für Temperatur, Sonnenscheindauer und Windgeschwindigkeit in der SQL-Datenbank. Um mit dem gleichen Datenbestand zu arbeiten, muss ein möglichst automatisierter Export und Import aus der SQL-Datenbank erfolgen. Zeitlich getriggert, beispielsweise alle fünf Minuten, könnte dieser Export und Import automatisiert laufen. Eine entsprechende SQL-Abfrage bereitet diese Daten entsprechend auf.
Der Line-Protocol-Import kann dann über einen cronjob gesteuert mit dem Befehl influx erfolgen. Die entsprechende SQL-Abfrage für den Line-Protocol Import könnte so aussehen. Zu beachten ist, die erste Zeile enthält den Spaltennamen. Dieser kann mit sed -i „1d“ <dateiname> schnell gelöscht werden. Das Ergebnis ist dann eine Datei zum Import.
SELECT CONCAT(`sensordata`.`SENSORID`, ",",
CONCAT('ORT=SHS '), " ",
CONCAT(`sensordata`.`SCHLUESSEL`,'=',`sensordata`.`WERT`)," ",
UNIX_TIMESTAMP(STR_TO_DATE(CONCAT(sensordata.DATUM," ",sensordata.Zeit), '%Y-%m-%d %H:%i:%s'))) AS INFLUXDB
FROM `sensordata`
WHERE `sensordata`.`SENSORID` LIKE 'DWDWEATHER' AND `sensordata`.`SCHLUESSEL` LIKE 'Temperature'Der Import erfolgt mit folgendem Befehl:
docker exec <Name_of_influxDB-Docker-Container>\
influx write \
-o "ORG-Name" \
-b "BUCKET-Name" \
-t "**********==" \
-p "s" \
-f "<sharedpath_and_filename_for_import"Das alles kann in eine Batch Datei verpackt werden und alle 5 Minuten (oder beliebiges Intervall) gestartet werden.
Sobald der Import funktioniert und automatisch die Daten übertragen werden kann in grafana eine weitere Quelle konfiguriert und ein entsprechendes Dashboard aufgebaut werden.

Die Darstellung der Temperatur ist eine einfache Zeitreihe mit begrenzter Datenmenge. Dieses data set ist gut geeignet um den generellen Ablauf und die Technik zu validieren. Die Darstellung des Solarpaneldasboards ist dagegen umfangreicher und enthält ein Vielfaches an Daten. Das Board umfasst je ein Chart für jedes Panel, ein Chart für die Gesamtleistung und Chart für die aktuelle Leistung. Auf Basis der SQL Datenbank dauert die Aktualisierung zwischen 15 und 30 Sekunden.
Auf Basis der Temperaturdaten werde ich als nächstes die InfluxDB mit einem Bucket und einer Retention time von einem Tag dafür aufbauen. Durch den periodischen Import gibt es die Daten zwar nicht in Echtzeit aber ein Delay von 5 Minuten ist sicherlich vertretbar, wenn die Daten dafür auf Knopfdruck zur Verfügung stehen.
Das Ergebnis gibt es dann in einem folgenden Beitrag.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hinterlasse einen Kommentar